首先我们要知道什么是爬虫! 当我第一次看到reptile这个词时,我以为它是爬行动物。 想想都觉得可笑……后来才知道那是网上的一个数据抓取工具!
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中更常见的称为网络追逐者)是一种按照一定规则自动抓取万维网信息的程序或脚本。 其他不太常用的名称包括蚂蚁、自动索引器、模拟器或蠕虫。
爬虫能做什么?
模拟浏览器打开网页,获取网页中我们想要的部分数据。
从技术角度来说,程序模拟浏览器请求站点的行为,将站点返回的HTML代码/JSON数据/二进制数据(图片、视频)抓取到本地,然后提取出你需要的数据并存储用来。
如果仔细观察,不难发现越来越多的人了解和学习爬虫。 一方面,可以从互联网上获取越来越多的数据。 另一方面php爬虫教程,像Python这样的编程语言提供了越来越多优秀的工具,使爬虫变得简单易用。
利用爬虫,我们可以获得大量有价值的数据,获得通过感性认识无法获得的信息,比如:
知乎:抓取优质答案php爬虫教程,为您筛选出每个主题的最佳内容。
淘宝、京东:抓取商品、评论、销售数据,分析各类商品及用户消费场景。
安居客和链家:捕捉房产销售和租赁信息,分析房地产市场变化趋势,分析不同地区的房产价格。
拉勾网、智联招聘:抓取各种职位信息,分析各行业的人才需求和薪资水平。
Snowball.com:捕捉Snowball高回报用户行为,分析预测股市等。
爬虫的原理是什么?
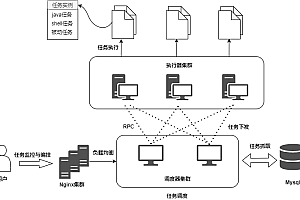
发送请求 > 获取响应内容 > 解析内容 > 保存数据
如上图,这就是爬取数据时的流程。 是不是很简单呢? 因此,用户听到的浏览器结果是由HTML代码组成的。 我们的爬虫就是通过对HTML代码进行分析、过滤来获取那个内容,从而获得我们想要的资源。