为了学习Golang的底层知识,装酷,就折腾了编译器相关的知识。 以下内容不会增加你的制作技能点,但可以增加你的酷感指数。 请按需阅读!
快速概述本文的内容:
认识 gobuild
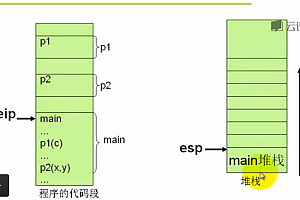
当我们输入gobuild时,我们编写的源代码文件发生了什么? 终于得到可执行文件了。
这条命令将会编译go代码,明天我们来看看go编译过程吧!
首先我们先来了解一下下面的go代码源文件分类
gobuild命令用于编译命令源码文件及其依赖的库源码文件。 下表是一些常用的选项,集中在这里。
选项说明
-A
重建所有命令源代码文件和库源代码文件,尽管它们是最新的
-n
将编译期涉及到的命令全部复制,但是不会执行,这对于我们学习来说非常方便
-种族
启用竞争条件检查golang源码怎么编译,支持的平台有限
-X

复制编译时使用的命名,它和-n的区别是除了复制之外还会执行
然后使用 helloworld 程序演示以下命令选项。
如果我们对里面的代码执行gobuild -n,我们看一下输出信息:
分析整个执行过程
这部分是编译的核心,会通过compile、buildid、link三个命令编译出可执行文件a.out。
然后使用mv命令将a.out链接到当前文件夹,并更改为与项目文件同名(这里也可以自己指定名称)。
文章下一部分主要讲一下compile、buildid、link这三个命令所涉及到的编译过程。
编译原理
这是go编译器的源码路径
从上图中可以看到,整个编译器可以分为:编译后端和编译前端; 现在让我们看看编译器在每个阶段做了什么。 我们先从后端开始。

词法分析
词法分析简单来说就是把我们写的源码翻译成Token。 这是什么意思?
为了理解Golang从源码翻译成Token的过程,我们用一段代码来看一下翻译的一一对应关系。
图中重要的地方我都注释掉了,不过这里多说几句。 让我们看一下前面的代码并想象以下内容。 如果我们想自己实现这个“翻译工作”,那么程序如何识别Token呢?
首先,我们将 Go 的 token 类型分为几类:变量名、文字、运算符、分隔符和关键字。 我们需要按照规则拆分一堆源代码,当然它们是动词。 看看前面的示例代码,我们可以大致制定一个规则如下:
识别空格,如果是空格,就可以分成单词; 遇到(、)、''等特殊运算符时,算作动词; 当它遇到“或数字文字时,它被算作动词。
通过前面的简单分析,虽然可以看出源码到token的转换并不是特别复杂,但是自己写代码就可以实现。 事实上,还有很多更通用的词法分析器以正则化的形式实现。 比如Golang早期使用的是lex,在之前的版本中只使用go来实现。
句子分析
经过词法分析后,我们收到的是 Token 序列,它将作为句子解析器的输入。 处理后,生成 AST 结构作为输出。
所谓句型分析,就是将Token转换成可识别的程序句子结构,AST就是这个句型的具体表示。 有两种方法可以构建这棵树。
自顶向下
这些方法会首先构造根节点,然后开始扫描Token。 当你遇到STRING或者其他类型时,你就会知道这是一个类型声明,而func的意思是函数声明。 这样,扫描就一直持续到程序结束。
自下而上

这些与前面的方法相反,前面的方法首先构造子树,然后将它们组装成完整的树。
Go语言采用自下而上的句型分析方法来构建AST。 接下来我们看看Go语言通过Token构建的树长什么样。
里面有趣的地方我都用文字标注了。 你会发现AST树的每个节点都对应着一个Token的实际位置。
树构建完成后,我们可以看到不同的类型由对应的结构体来表示。 如果这里有句型或者词汇错误golang源码怎么编译,就不会被解析。 因为到目前为止都是关于字符串处理的。
语义分析
在编译器中,句型分析之后的阶段称为语义分析,Go的这个阶段称为类型检测; 我已经阅读了以下 Go 自己的文档。 虽然我们做的事情没有太大区别,但我们还是遵循主流规范。 写一下过程。
那么语义分析(类型检测)到底应该做什么呢?
AST生成后,语义分析会用它作为输入,但一些相关操作也会直接在这棵树上重写。
首先,Golang文档中提到,会进行类型检测和类型推断,检查类型是否匹配以及是否进行隐式转换(go没有隐式转换)。 正如下面的文字所说:
然后对 AS 进行类型检查。 第一步是名称解析和类型推断,确定哪个对象属于哪个标识符,以及每个表达式的类型。 类型检查包括某些额外的检查,例如“声明但未使用”以及确定其他函数是否终止。
大致思路是:AST生成后,进行类型检测(也就是我们这里说的语义分析),第一步是进行名称检测和类型推断,确定每个对象所属的标识符,并每个表达式有哪些类型。 类型检查还需要执行一些其他检查,例如“声明未使用”并确定函数是否终止。
某些转换在 AST 上是真正完成的。 有些节点是根据类型信息进行细化的,例如从算术加法节点类型中拆分出字符串加法。 其他一些示例包括死代码消除、函数调用内联和转义分析。
这一段说的是:AST也会进行转换,并且根据类型信息对一些节点进行简化,比如从算术乘法节点类型中拆分出字符串除法。 其他一些反例,如死代码清理、函数调用内联和转义分析。

里面两段来自golangcompile
这里再多说一句,我们在调试代码的时候往往需要严格禁止内联,虽然是这个阶段的操作。
# 编译的时候禁止内联
go build -gcflags '-N -l'
-N 禁止编译优化
-l 禁止内联,禁止内联也可以一定程度上减小可执行程序大小经过语义分析,可以证明我们的代码结构和语法是正确的。 所以编译器后端主要是解析出编译器前端可以处理的正确的AST结构。
把它拿出来看看编译器前端还做什么。
机器只能理解并运行二进制补码代码,因此编译器的前端任务简单来说就是如何将 AST 翻译成机器代码。
中间代码生成
现在 AST 已经收到了,机器需要运行的是二进制补码。 为什么不直接翻译成二进制补码呢? 虽然目前为止从技术上来说,完全没有问题。
然而,
我们有各种操作系统和不同的CPU类型,每种类型的位数可能不同; 只能由寄存器使用的指令也不同,例如复杂指令集和简化指令集等; 各平台的兼容性之前,我们还需要替换一些底层函数,比如我们使用make来初始化切片,此时会根据传入的类型替换为:makeslice64或者makeslice。其实替换就是painc、channel等函数在中间代码生成过程中也会被替换。这部分的替换操作可以查看这里
中间代码的另一个价值是提高前端编译的复用性。 比如我们定义了一组中间代码应该是什么样子,这样前端机器代码的生成就相对固定了。 每种语言只需要完成自己的编译器后端工作。 这就是为什么您现在可以看到开发新语言更快的原因。 编译大部分是可重用的。
但对于后续的优化工作来说,中间代码的存在却有着非同寻常的意义。 因为平台太多了,如果有中间代码的话,我们可以把一些常见的优化放在这里。
中间码也有多种格式。 例如,Golang使用具有SSA特性的中间代码(IR)。 这些中间代码最重要的特点是,变量总是在使用变量之前定义,但每个变量只分配一次。
代码优化

在go的编译文档中,我没有找到一个独立的步骤来优化代码。 然而,根据我们内部的分析,我们可以看到,虽然代码优化过程充满了编译器的每一个阶段。 你会尽力而为。
一般来说,我们不仅用高效的代码替换低效的代码,还会做以下事情:
机器代码生成
优化后的中间代码在这个阶段首先会被转换为汇编代码(Plan9),而汇编语言只是机器代码的文本表示,机器并不能真正执行它。 所以这个阶段会调用汇编器,汇编器会根据我们在执行编译时设置的框架,调用相应的代码生成目标机器码。
这里更有趣的是,Golang 总是说它的汇编器是跨平台的。 虽然他也写了多段代码来翻译最终的机器码。 因为在入口的时候,它会根据我们设置的GOARCH=xxx参数进行初始化处理,然后最终调用对应框架编译的具体方法生成机器码。 这些底层逻辑是一致的,底层逻辑不一致的情况也很常见,特别值得学习。 让我们简单地做一下。
首先看入口函数cmd/compile/main.go:main()
var archInits = map[string]func(*gc.Arch){
"386": x86.Init,
"amd64": amd64.Init,
"amd64p32": amd64.Init,
"arm": arm.Init,
"arm64": arm64.Init,
"mips": mips.Init,
"mipsle": mips.Init,
"mips64": mips64.Init,
"mips64le": mips64.Init,
"ppc64": ppc64.Init,
"ppc64le": ppc64.Init,
"s390x": s390x.Init,
"wasm": wasm.Init,
}
func main() {
// 从上面的map根据参数选择对应架构的处理
archInit, ok := archInits[objabi.GOARCH]
if !ok {
......
}
// 把对应cpu架构的对应传到内部去
gc.Main(archInit)
}然后调用cmd/internal/obj/plist.go中对应的框架进行处理
func Flushplist(ctxt *Link, plist *Plist, newprog ProgAlloc, myimportpath string) {
... ...
for _, s := range text {
mkfwd(s)
linkpatch(ctxt, s, newprog)
// 对应架构的方法进行自己的机器码翻译
ctxt.Arch.Preprocess(ctxt, s, newprog)
ctxt.Arch.Assemble(ctxt, s, newprog)
linkpcln(ctxt, s)
ctxt.populateDWARF(plist.Curfn, s, myimportpath)
}
}整个流程下来,可以看到编译器前端还有很多工作要做。 你需要了解一定的指令集和CPU架构才能正确翻译机器代码。 同时,它也不可能只是正确的。 一种语言的效率高低很大程度上取决于编译器前端的优化。 尤其是我们正式进入AI时代,越来越多的芯片厂商诞生。 恐怕未来这方面的人才需求会越来越旺盛。
总结
总结一下我学习编译器古老知识的几点收获:
知道整个编译是由几个阶段组成的,以及每个阶段做什么的; 而每个阶段更深层次实施的一些细节目前还不知道,也不准备知道; 即使像编译器这样复杂且非常底层的东西也可以通过分解,让每个阶段变得简单并且可以独立复用,这对于我在应用程序开发中具有一定的意义; 分层是为了定义谴责,但是个别的事情需要全局去做,比如优化,虽然每个阶段都是我来做; 对我们的设计系统也有一定的参考意义; 我了解到,虽然Golang对外接触的很多方式都是语句糖(如:make、pain等),但是编译器会帮我翻译。 起初我以为它是在Go代码级别的运行时完成的,类似于鞋厂模型。 现在回想起来,我真是太天真了; 我打算学习Go的运行机制,并为Plan9的编译制定了一些基本计划。
本文中的大部分信息均来自以下来源。


![编译驱动的内核源码-[OpenWrt] 使用SDK编译Linux内核驱动](https://www.wkzy.net/wp-content/themes/ceomax/timthumb.php?src=https://www.wkzy.net/wp-content/uploads/2024/04/1714318441748_1.png&h=200&w=300&zc=1&a=c&q=100&s=1)