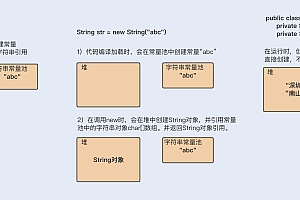
前言
最近有一个案例。 需要解析word文档。 有两个需求,一是将word文档转换为PDF,二是将word文档中的内容按照一定的规范读取到数据库中。 我去npm仓库找了大概十几个包,发现主要是通过下面的方法来转换代码。
后来我退而求其次,找到了一个texttract包,先把docx转成文本。
当然,也有缺点。 不支持docx中的标题编号,也不支持图片等文件。

我不怕死javascript读取xml,决定自己做。
介绍
其实docx就是一个zip包,然后封装了一些xml文件。 您可以直接将docx包的后缀更改为.zip来打开观看。

粘贴_图像.png
输入word文件夹
粘贴_图像.png

里面有几个主要文件。
document.xml 这是文档的主要内容
numbering.xml 这是标题编号,以及标题编号的一些属性
styles.xml 这是样式列表

打开document.xmljavascript读取xml,你会发现所有的文本都被标签包裹住了。这就是本文的关键
代码
最近,我正在使用node.js来解析docx。 先写最简单的,有时间再回去继续分享
2月13日更新

之前手写的代码,今天测试发现使用更新后的代码效率比源码高十倍以上。
//原代码
//str += item.replace("","").replace("","");
//更新代码
str += item.slice(5,-6)附上测试代码
var str = "sdfjpasif aefnmasd;lf asdfsdf";
var arr = [];
for(var i=0;i<50000;i++){
arr.push(str);
}
console.time("replactest");
arr.forEach((item)=>{
item.replace(//,"").replace(//,"");
});
console.timeEnd("replactest");
//replactest: 20.560ms
console.time("replactest2");
arr.forEach((item)=>{
item.replace(//g,"");
});
console.timeEnd("replactest2");
//replactest2: 14.926ms
console.time("replactest3");
arr.forEach((item)=>{
item.replace(/(^)|($)/g,"");
});
console.timeEnd("replactest3");
//replactest3: 14.402ms
console.time("slice");
arr.forEach((item)=>{
item.slice(5,-6);
});
console.timeEnd("slice");
//slice: 1.718ms