我们大多数人都拥有我们不知道的能力和机会,并且我们都有潜力做我们从未梦想过的事情。 - 戴尔卡耐基
从后端转到Node.js的童鞋会对这部分比较陌生,因为后端一些简单的字符串操作已经满足了基本的业务需求,有时候可能会觉得Buffer和Stream很神秘。 回到服务器端,如果你不想只是一名普通的 Node.js 开发工程师,你应该更多地了解 Buffer 来揭开这层神秘面纱,同时将你对 Node.js 的理解提升到一个更深入的水平。更高层次 。
作者简介:May Jun,Nodejs 开发者,热爱技术、热爱分享的 90 后青年,公众号“Nodejs 技术栈”,Github 开源项目
快速导航
Buffer的基本使用
缓冲存储器机制
缓冲区应用场景
缓冲区 VS 缓存
缓冲区 VS 字符串
面试指南Buffer介绍
在引入 TypedArray 之前,JavaScript 语言没有读取或操作二进制数据流的机制。 Buffer 类作为 Node.js API 的一部分引入,用于与 TCP 流、文件系统操作和其他上下文中的八位字节流进行交互。 这是来自Node.js官网的描述,比较深奥,难以理解。 综上所述,Node.js 可用于处理二进制流数据或与之交互。
缓冲区用于读取或操作二进制数据流。 当作为 Node.js API 的一部分使用时,它不需要 require。 用于操作需要大量二进制数据的网络合约、数据库、图像、文件I/O场景。 Buffer的大小在创建时就已经确定了,很难调整。 内存分配的Buffer是C++级别提供的,而不是V8。 这将在上一节中进行解释。
不知道看到这里你是不是觉得很简单呢? 但是上面提到的一些关键字是什么呢,binary、stream、buffer? 我们尝试做一些简单的介绍。
什么是二进制数据?
说到二进制,我们脑子里可能会想到010101这样的代码命令,如下图所示:
如上图所示,二进制数据是由0和1两个数字来表示的。为了存储或显示一些数据,计算机首先必须将这些数据转换为二进制表示形式。 例如,如果我要存储数字66,计算机首先会将数字66转换为二进制表示形式01000010。我第一次接触这个是在大学期间的C语言课程中。 换算公式如下:
1286432168421
上面用数字给出了一个例子。 我们知道数字只是其中一种数据类型,还有其他的字符串、图像、文件等。比如我们对中文M进行操作时,通过 'M'.charCodeAt() 获取对应的ASCII码后JavaScript(通过上述步骤),会将其转换为二进制表示形式。
什么是流?
流,英文Stream是输入输出设备的具体表示,其中设备可以是文件、网络、内存等。
流是有方向的。 当程序从数据源读取数据时,将打开一个输入流。 这里的数据源可以是文件,也可以是网络。 例如,我们从.txt文件中读取数据。 相反,当我们的程序需要将数据写入指定的数据源(文件、网络等)时,就会打开一个输出流。 当有一些大文件操作时,我们需要Stream像管道一样将数据一点一点地流出。
举个反例

我们现在有一大盆水需要浇灌菜园。 如果我们一下子把水罐里的水全部倒进菜园里,首先需要多大的力气(这里的力气就像电脑里的硬件性能)才能把它搬动。 如果我们用水管将水一点一点地流进我们的菜园里,这时候就可以不用那么费力了。
通过前面的讲解,对Stream的进一步理解是什么呢? 那么Stream和Buffer是什么关系呢? 请看下面的介绍。 Stream本身也有很多知识点。 欢迎关注公众号“Nodejs技术栈”,稍后我会单独介绍。
什么是缓冲区?
通过上面对Stream的讲解,我们已经听说了数据从一端流向另一端,那么它们是如何流动的呢?
通常,传输数据是为了处理或读取数据并据此做出决策。 随着时间的推移,每个进程还具有最小或最大数据量。 如果数据到达的速度快于进程消耗它的速度,则较早到达的少数数据将位于等待区域等待处理。 相反,如果数据到达的速度比进程消耗的数据慢,则最初到达的数据将必须等待一定量的数据到达才能被处理。
这里的等待区指的是缓冲区(Buffer),它是计算机中的一个小型化学单元,通常位于计算机的RAM中。 这些概念可能很难理解,不要害怕通过下面的例子进一步解释。
在公交车站上车的示例
以在公交车站乘坐公交车为例。 通常,公共汽车每隔几分钟就会运行一次。 即使这个时间之前乘客已经满了,巴士也不会提前出发。 等待。 如果到达的乘客太多,其中一些人将需要在公交车站等待下一班车的到来。
示例中等候区的公交车站对应于我们 Node.js 中的缓冲区。 此外,乘客到达的速度也是我们无法控制的。 我们能控制的是总线什么时候出发,对应的是在我们的程序中,我们很难控制数据流的到达时间。 我们能做的就是决定何时发送数据。
缓冲区基本使用
了解了Buffer的一些概念后,我们来看看Buffer的一些基本用法。 这里并没有列出所有用到的API,只是列出了一些常用的。 更多详情请参考Node.js中文网站。
创建缓冲区
在 6.0.0 之前的 Node.js 版本中,Buffer 实例是使用 Buffer 构造函数创建的,该构造函数根据提供的参数以不同的方式分配返回的 Buffer newBuffer()。
现在可以通过三种形式创建:Buffer.from()、Buffer.alloc() 和 Buffer.allocUnsafe()
缓冲。 从()
const b1 = Buffer.from('10');
const b2 = Buffer.from('10', 'utf8');
const b3 = Buffer.from([10]);
const b4 = Buffer.from(b3);
console.log(b1, b2, b3, b4); //
缓冲区分配
返回一个初始化的Buffer,保证新创建的Buffer永远不会包含旧数据。
const bAlloc1 = Buffer.alloc(10); // 创建一个大小为 10 个字节的缓冲区
console.log(bAlloc1); //
缓冲。 分配不安全
创建一个大小为字节的新的未初始化缓冲区。 由于Buffer未初始化,分配的视频内存段可能包含敏感的旧数据。 当Buffer内容可读时,其旧数据可能被窃取。 这并不安全,所以使用时要小心。
const bAllocUnsafe1 = Buffer.allocUnsafe(10);
console.log(bAllocUnsafe1); //
缓冲区字符编码
通过使用字符编码,可以实现Buffer实例和JavaScript字符串之间的转换。 目前支持的字符编码如下:
const buf = Buffer.from('hello world', 'ascii');
console.log(buf.toString('hex')); // 68656c6c6f20776f726c64
string和Buffer类型之间的转换
字符串到缓冲区
相信这并不陌生。 它是通过前面解释的 Buffer.form() 实现的。 如果不传递编码,则默认按照UTF-8格式转换存储。
const buf = Buffer.from('Node.js 技术栈', 'UTF-8');
console.log(buf); //
console.log(buf.length); // 17
缓冲区转换为字符串
将Buffer转换为字符串也很简单。 使用 toString([encoding], [start], [end]) 方法。 默认编码仍然是UTF-8。 如果不通过start和end,所有的转换都可以实现。 通过 start 和 end 可以进行部分转换(这里要小心)
const buf = Buffer.from('Node.js 技术栈', 'UTF-8');
console.log(buf); //
console.log(buf.length); // 17
console.log(buf.toString('UTF-8', 0, 9)); // Node.js �
运行查看,可以看到上述输出结果在Node.js中都是乱码,为什么呢?
为什么转换时会出现乱码?
首先,上例中使用的默认编码方式是UTF-8。 问题是UTF-8下一个英文单词占用3个字节。 buf中的Technology这个字对应的字节是8a80e6,我们设置的范围是0到9,所以只输出8a。 只有这个时候字符才会被截断,出现乱码。
让我们改变下面例子的拦截范围:
const buf = Buffer.from('Node.js 技术栈', 'UTF-8');
console.log(buf); //
console.log(buf.length); // 17
console.log(buf.toString('UTF-8', 0, 11)); // Node.js 技
可以看到输出已经正常了
缓冲存储器机制
Node.js中的内存管理和V8垃圾回收机制这一节主要讲解了Node.js的垃圾回收中主要是如何使用V8来进行管理的,但是并没有提及Buffer类型的数据是如何被回收的。 下面我们来了解一下Buffer。 内存回收机制。
由于Buffer需要处理大量的二进制数据,如果稍微向系统申请的话,就会导致系统频繁申请显存调用,所以Buffer占用的显存不再由V8分配,但在 Node.js 中,应用是在 C++ 级别完成的,内存分配是在 JavaScript 中进行的。 因此,这部分显存称为堆外显存。
注:下面使用的buffer.js源码是Node.js v10.x版本,地址:
缓冲存储器分配原则
Node.js采用slab机制进行预申请和后分配,这是一种动态管理机制。
使用Buffer.alloc(size)传入指定大小将申请固定大小的显存区域。 该slab有以下三种状态:
8KB限制
Node.js 以 8KB 为边界来区分是小对象还是大对象。 可以在buffer.js中看到如下代码
Buffer.poolSize = 8 * 1024; // 102 行,Node.js 版本为 v10.x
在Buffer简介一节中提到,Buffer的大小在创建的时候就已经确定了,很难调整。 这里应该明白了。
缓冲区对象分配
在下面的代码示例中,加载时直接调用createPool()相当于直接初始化8KB显存空间,这样第一次分配显存时效率会更高。 另外,初始化的同时还初始化了一个新的变量poolOffset = 0。 该变量将记录已经使用了多少字节。
Buffer.poolSize = 8 * 1024;
var poolSize, poolOffset, allocPool;
... // 中间代码省略
function createPool() {
poolSize = Buffer.poolSize;
allocPool = createUnsafeArrayBuffer(poolSize);
poolOffset = 0;
}
createPool(); // 129 行
此时,新构建的slab如下所示:
现在让我们尝试分配一个大小为2048的Buffer对象,代码如下:
Buffer.alloc(2 * 1024)
现在我们来看看现在的slab内存是什么样子的? 如下:
那么分发过程是怎样的呢? 我们来看buffer.js的另一个核心方法allocate(size)
// https://github.com/nodejs/node/blob/v10.x/lib/buffer.js#L318
function allocate(size) {
if (size <= 0) {
return new FastBuffer();
}
// 当分配的空间小于 Buffer.poolSize 向右移位,这里得出来的结果为 4KB
if (size < (Buffer.poolSize >>> 1)) {
if (size > (poolSize - poolOffset))
createPool();
var b = new FastBuffer(allocPool, poolOffset, size);
poolOffset += size; // 已使用空间累加
alignPool(); // 8 字节内存对齐处理
return b;
} else { // C++ 层面申请
return createUnsafeBuffer(size);
}
}
读完前面的代码,你可以清楚地看到什么时候会分配一个小Buffer对象,什么时候会分配一个大Buffer对象。
缓冲存储器分配总结
这段内容确实很难理解。 看了几本Node.js相关的书籍,朴凌老师的《轻松学Node.js》Buffer部分讲得相当详细。 我推荐你读一下。
仅在第一次加载时才会初始化8KB显存空间,高亮buffer.js源码
根据请求显存大小,分为小Buffer对象和大Buffer对象
在Buffer较小的情况下,会继续判断slab空间是否足够
当Buffer较大的情况下,会直接使用createUnsafeBuffer(size)函数
不管是小Buffer对象还是大Buffer对象,内存分配都是在C++级别完成的,内存管理是在JavaScript级别完成的javascript 字符是数字,最终都可以通过V8的垃圾回收标志来回收。
缓冲区应用场景
下面列出了Buffer在实际业务中的一些应用场景,欢迎大家在评论区补充!
输入/输出操作
对于I/O,可以是文件I/O,也可以是网络I/O。 下面是通过stream的方法读取input.txt的信息,然后写入到output.txt文件中。 如果你不明白Stream和Buffer的关系,回头看看什么是Stream、什么是Buffer?
const fs = require('fs');
const inputStream = fs.createReadStream('input.txt'); // 创建可读流
const outputStream = fs.createWriteStream('output.txt'); // 创建可写流
inputStream.pipe(outputStream); // 管道读写
在 Stream 中,我们不需要自动创建自己的缓冲区,它将在 Node.js 流上手动创建。
zlib.js
zlib.js 是 Node.js 的核心库之一。 它利用缓冲区(Buffer)的功能来操作二进制数据流,并提供压缩或解压缩的功能。参考源码 zlib.js 源码
再加上揭秘
在一些加解密算法中javascript 字符是数字,会用到Buffer。 例如crypto.createCipheriv的第二个参数key是String或者Buffer类型。 如果是Buffer类型,就使用我们这篇文章中讲解的内容。 下面做了一个简单的加密举例,重点是使用Buffer.alloc()初始化一个实例(本节介绍),然后使用fill方法进行填充。 这里,重点是该技术的使用。
buf.fill(值[, 偏移量[, 结束]][, 编码])
以下是Cipher的对称加密Demo
const crypto = require('crypto');
const [key, iv, algorithm, encoding, cipherEncoding] = [
'a123456789', '', 'aes-128-ecb', 'utf8', 'base64'
];
const handleKey = key => {
const bytes = Buffer.alloc(16); // 初始化一个 Buffer 实例,每一项都用 00 填充
console.log(bytes); //
bytes.fill(key, 0, 10) // 填充
console.log(bytes); //
return bytes;
}
let cipher = crypto.createCipheriv(algorithm, handleKey(key), iv);
let crypted = cipher.update('Node.js 技术栈', encoding, cipherEncoding);
crypted += cipher.final(cipherEncoding);
console.log(crypted) // jE0ODwuKN6iaKFKqd3RF4xFZkOpasy8WfIDl8tRC5t0=
缓冲区 VS 缓存

缓冲区和缓存有什么区别?
缓冲
缓冲区(Buffer)用于处理二进制流数据并对数据进行缓冲。 这是暂时的。 对于流式数据,缓冲区会用来暂时存储数据,缓冲到一定大小后才会存储到硬盘中。 中间。 视频播放器就是一个典型的例子。 有时你会看到一个缓冲区图标,这意味着此时这组缓冲区尚未满。 当数据到达满缓冲区并已被处理时,缓冲区图标消失,您可以听到一些图像数据。
缓存
Cache可以看作是一个中间层,可以永久缓存热点数据,使访问速度更快。 比如我们通过Memory、Redis等向硬盘或者其他第三方socket请求数据,缓存的目的就是将数据存储在显存的缓存区域中,这样对同一个资源的访问就可以了。更快,也是性能优化的一个重点。
来自知乎的讨论,点击更多查看
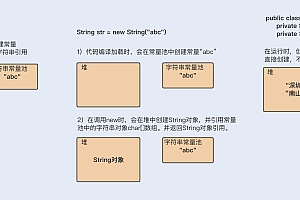
缓冲区 VS 字符串
通过压力测试,String和Buffer的性能如何?
const http = require('http');
let s = '';
for (let i=0; i<1024*10; i++) {
s+='a'
}
const str = s;
const bufStr = Buffer.from(s);
const server = http.createServer((req, res) => {
console.log(req.url);
if (req.url === '/buffer') {
res.end(bufStr);
} else if (req.url === '/string') {
res.end(str);
}
});
server.listen(3000);
我把上面的例子放在虚拟机中进行测试,你也可以在本地笔记本上测试,使用AB测试工具。
测试字符串
看下面几个重要参数指标,然后通过缓冲传输进行比较
$ ab -c 200 -t 60 http://192.168.6.131:3000/string
测试缓冲液
可以看到,通过缓冲区传输的请求总数为5万个,QPS增加了一倍多,每秒传输的字节数为9138.82 KB。 从这些数据可以证明,提前将数据转换成Buffer的方法可以将性能提高几乎一倍的提升。
$ ab -c 200 -t 60 http://192.168.6.131:3000/buffer
二进制数据在HTTP传输中传输。 上例中的/string接口直接返回一个字符串。 这时,HTTP在传输之前会先将字符串转换为Buffer类型,并以二进制数据的形式通过流(Stream)的形式一点一点地返回给客户端。 然而,直接返回Buffer类型减少了每次转换操作的需要,这也提高了性能。
在一些Web应用中,静态数据可以提前转换为Buffer进行传输,这样可以有效减少CPU的复用(重复的字符串到Buffer操作)。
参考
本文经作者“马月君”授权转载。 原文发表于公众号“Nodejs技术栈”。 您可以点击查看原文。
欢迎贡献。