底漆
我曾经听一位学理科的朋友讲过他朋友的轶事:这位朋友会写一个小程序来帮他解决任何需要5秒以上、不需要动脑子、并且能够完成的任务。待完成。 不用说,工作中的邮件往来,甚至在讨论项目的工作组中,都是交给小程序手动处理。 检测到有人说话、内容与你的工作相关、或者有人@你自己等,连接句库进行手动回复。
我听后很是羡慕。 如果我们司法人员懂得编程,将会节省很多时间。 例如,将办案系统、摘录证据等填写到笔记本中,不仅可以节省精力、减少错误,还可以节省分析案件中的证据材料和法律关系的时间。
带着程序员的羡慕,加上各种机缘巧合,我开始了自己的Python之旅。 现在我稍微尝到了编程的好处和乐趣。 例如,我们在工作中需要查询大量的法律文件、文件。 如果只有一两个,我们可以直接从网页上下载。 但如果需要操作的副本很多,那就很不方便了。 爬虫功能可以轻松地为我们完成这个要求,还可以顺便删除各种广告等不相关的内容。
下面以法律专业人士会接触到的判决书网为例,简单介绍一下爬虫功能的实现。 熟练掌握后,下载我们需要的大量裁判文档就非常简单,几分钟就可以完成。
文本
1. 准备工作
在开始之前,我们先简单介绍一下Python以及一些基本问题。
Python是一种笔记本语言,句型简单,模块较多。 可以轻松实现很多功能; 并且您不必担心如何实施它。 只要找到合适的模块并告诉它去做,它非常适合非程序。 会员开始。 不得不说,这对于需要检索大量信息的法律专业人士来说,实在是一个福音。
比如我们要从网上抓取数据,如果用其他语言来编译程序,就会需要很多行,非常麻烦。 然而,在 Python 中,几行就可以解决问题。
选择Python后,有两个问题需要确定,语言版本和模块。 从语言版本来看,主要有2.7和3两种。2.7的优点是“历史悠久”,可以使用的模块较多; 3的优点是符合未来的发展方向,而且我们能使用的大部分模块都已经支持了,而且使用过程中对英文的支持要好很多。 所以我个人推荐直接使用3。 当然,这些对于我们外行来说并不是很重要。 两者都差不多,只要能用就行,不要卷入程序员之间的口水战。
另外,这是一个模块问题。 模块就像日常工作中的笔、纸、砚等工具。 它节省了我们自己“制作工具”的时间。 这里我推荐Anaconda。 和普通软件一样,你只需要在谷歌或百度搜索它,从其官方网站下载并安装,你的笔记本就可以像Python一样编程。 我们需要的这些模块已经打包安装在一起了,这样就节省了我们寻找模块、安装模块以及处理模块之间兼容性的时间。 可以说是工具中的工具。
综上所述,准备工作可以用一句话来概括:
搜索 Anaconda 并下载! 安装! 完毕!
2. 爬虫入门
互联网是一个网络,为我们在互联网上搜索信息的程序就是爬虫。
我们要做的司法文书网站比普通网站要复杂一些,无法直接使用URL进行爬取。 因此,我们首先要明白两个问题。 一是在线显示的文件内容从哪里发送,二是网站必须满足什么条件才能向我们发送该内容。
1. 追踪网页:
登录中国裁判文书网首页,在搜索框中输入“执行”二字。
直接搜索“执行”二字。 确认后,我们在浏览器上可以看到的URL如下:

但是,这样做后,您将看到每篇文章的标题链接,并且无法直接捕获内容。 那么该怎么办?
我们需要使用软件网页进行跟踪。 该软件不需要安装。 无论是IE还是Chrome,如果按F12,都会手动弹出该软件。 我们以 Chrome 为例。
按F12后,右侧弹出软件界面。 选择右上角的网络项,刷新网页。 所有浏览器和网站之间的交互内容都出现在下面的name项中网站独立下载页源码,其中包含了我们想要的内容。 在该网页中,拉动两侧的浮动条即可找到Listcontent。 嗯,内容就静静地隐藏在圈起来的Listcontent项下。
我们选择列表内容。 从右边Headers的详细描述中可以看到,请求方式是POST,Request URL后面的是真正的内容请求地址。
如果你仍然进行前面的操作,你会发现:
你打开了新世界的大门。
接下来我们一起来解决第二个问题:
我们要发送什么内容才能让这个URL返回我们需要的信息? 同样在这个界面中,我们继续向下滚动,我们可以看到Form Data的内容(如下图)。

我们可以看到上面红框中的信息是:
param:搜索条件“全文搜索:执行”;
索引:1(首页);
页数:5(每页出现5个文档,最大值为20,我们可以在程序中直接设置为20);
order:法院级别(按法院级别排序);
最后一个参数已解码,复制即可。 按照这个格式将内容发送到网页上,然后我们就可以得到我们想要的信息了。
2. 代码
现在您已经知道以什么格式发送信息以及将其发送到何处,是时候编写代码了。
接下来我们在已经下载、安装、准备好的Anaconda软件下打开上述的Spyder。 两者的关系就像Anaconda是win系统,spyder是记事本一样。 Spyder是一个负责编写代码的工具。

会出现如下界面:
右边我们就可以开始自己写代码了。 在进入具体代码之前,我先为初学者多说几句。
一是心理问题。 初学者通常会有两个疑问,1)不禁想知道为什么要这样写? 这样写的“法律依据”是什么? 这种问题是程序员中的精英考虑的,普通程序员没有想过。 我们非专业人士应该坚持使用的原则,只要能用就行。 法律的主业已经掌握好了,有兴趣再学也不晚。
如果你太感兴趣,一不小心就彻底改变了你的职业网站独立下载页源码,那么……恭喜你加入了高薪行业。 普通Python程序员的年薪中位数在18000左右,是的,18000、18000、18000,哈哈。 2)理解一个反例所涉及的所有问题固然好,但它会成为你刚入门时学习和操作的障碍。 虽然学习编程是学习一门语言,但它只是对着笔记本说的语言。 想想我们刚学英语的时候是怎么做的? 后退! 因此,对于初学者来说,学习编程最简单、最有效的方法就是我们先将代码一行一行地敲入笔记本中。 打字之后你就明白了。
第二是技术问题。 也有两个方面:1)“#”后面是注释,用来给你解释代码。 无需将其输入笔记本中。 如果输入的话,会被笔记本忽略,不会影响程序的运行。 2)对于代码来说,如果一处出错,笔记本就无法识别,尤其是符号和格式一定不能错。 ① 除英文单引号和双冒号括起来的内容外,所有符号都必须是英文输入法下的符号; ② 所有代码都写在最上面的方框里,但是如果有从属关系,请注意留四个空格(下面提到的代码涉及到一个while循环语句,就涉及到这个问题,我会在后面进一步解释)代码)。 如果句子太长,可以按 Enter 键。 计算机能够理解并且不会影响程序的运行。
现在让我们开始吧!
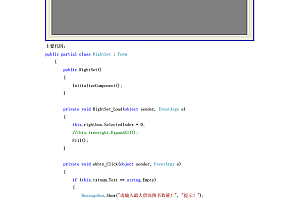
以下代码的作用是搜索全文中包含“执行”一词的案件,并将时间、案件编号、案件名称提取到excel表格中。
#“””之前的段落是打开spyder界面时手动添加的,一般情况下不需要动它。
#这句话告诉笔记本解码方式是UTF-8编码。 我们可以简单理解为代码中添加英文即可。 建议每次编程时都添加。
#-*- 编码:utf-8 -*-
#笔记本中用(""" """)包裹的部分也被忽略。 主要是给人看的部分,就是代码第一次编译的时间和作者。 这是可以写也可以不写的部分。
”“”
Createdon 星期日 七月 24 23:11:55 2016
@作者:罗涛 北京市丰台检察院
”“”
#这里是导出模块。 以下模块分别用于网页抓取、数据处理与存储、时间、正则表达式。
将请求导入为 req
将pandas导入为pd
导入时间
进口
#这是我们刚刚通过F12找到的网页