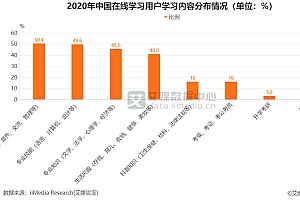
###答案1:Python爬虫可以使用Selenium库来爬取网页信息。 Selenium 可以模拟浏览器行为,以便爬取 JavaScript 渲染的网页信息。 使用Selenium爬取网页时,需要与浏览器驱动(如ChromeDriver、FirefoxDriver)配合使用。 ###答案2:Python是一种中级编程语言,吸引了大量程序员和开发者在Web开发、数据分析、机器学习、人工智能等领域使用Python进行开发。 爬虫技术是重要技术之一,一般用python来编译爬虫程序更加方便灵活。 Selenium 是 Python 中主要的爬虫库之一。 它用于抓取动态网页,可以模拟用户在浏览器中的行为,进而获取大量数据。 使用selenium爬取信息可以分为以下步骤: 1、安装并导出selenium和webdriver:首先需要安装合适版本的selenium包,并导出selenium和webdriver模块:```pythonfromseleniumimportwebdriver```2 。 配置浏览驱动程序:Selenium 需要浏览器驱动程序(例如 Chrome、Firefox 等)与其交互。 需要配置如下:```pythondriver=webdriver.Chrome()``` 其中,Chrome()表示使用Chrome浏览器驱动,如果要使用Firefox则需要改为Firefox()。
3.访问网页:使用get()函数访问指定的URL:```pythondriver.get("https://www.baidu.com/")``` 4.查找元素:使用selenium的搜索元素函数如何爬网站源码,可以根据元素的ID、名称、类、标签等属性进行查找:```pythonelement=driver.find_element_by_id("kw")#find element by ID=driver.find_element_by_name("wd") #按名称查找元素= driver.find_element_by_class_name("s_ipt")#按类查找元素=driver.find_element_by_tag_name("input")#按标签查找``` 5、模拟用户输入/点击:使用send_keys()函数来模拟用户在搜索框中输入关键词,使用 click() 函数模拟用户点击搜索按钮: ```pythonelement.send_keys("Python")element.click()``` 6. 解析数据:使用webdriver的page_source属性来获取网页的源代码,然后使用正则表达式或BeautifulSoup库等解析数据。
以上就是使用selenium爬取的主要步骤。 在实际应用中,需要根据不同的网站和要爬取的数据进行具体的配置和调整。 在使用selenium的过程中,需要了解一些常见的使用方法和注意事项,比如模拟等待时间、处理弹窗、验证码等,同时也需要遵守法律和法规遵守爬行动物道德,不从事非法和虐待行为。 ###答案3:selenium是一个手动测试工具,可以模拟浏览器行为,实现手动操作。 在Python爬虫中,selenium也可以用来爬取需要模拟手动操作的网站数据。 使用selenium可以实现以下操作: 1、手动模拟浏览器打开网页,获取网页源代码。 2. 模拟用户操作,如点击按钮、填写文本框、下拉选择框等。 3. 通过获取网页源代码进行数据分析。 基本过程比较简单。 首先需要准备selenium环境,需要下载对应的webdriver。 这里我使用的是Chrome浏览器,但是我下载了对应版本的chromedriver。 然后通过selenium启动浏览器如何爬网站源码,在浏览器中进行模拟操作,最终获取网页源代码进行数据分析。 具体实现可以参考如下代码: ```pythonfromseleniumimportwebdriverfrombs4importBeautifulSoup#创建Chrome浏览器实例 browser=webdriver.Chrome()#访问目标网页 browser.get('#39;)#模拟点击按钮,等待加载完成按钮=浏览器。 find_element_by_xpath('//button[@class="btn"]')button.click()browser.implicitly_wait(5)#获取网页源代码 html=browser.page_sourcesoup=BeautifulSoup(html,'html.parser')data= soup .find_all('div',class_='data')#处理数据 foritemindata:#dosomething#关闭浏览器 browser.quit()```总的来说,selenium 是一个强大的爬虫工具,可以处理大多数需要的模拟手动操作的场景,但也存在速度慢、资源消耗高等缺点。 因此,在具体应用中,需要根据实际情况进行选择。