前几天,iG夺冠,王老师在微博中中奖,113万元。
获奖结果出来后,有兴趣人士透露,113名获奖者中有112名是男性。
为什么总有一些人那么厉害,能够发现这种别人看不到的东西。 分析这个结果需要什么能力?
写代码? 数据分析? 或者其他的东西?
在这篇文章中,我将与大家分享一种普通人也可以分析王思聪抽奖名单的方式。
首先,要分析抽奖名单,你必须知道谁抽奖了。 这些信息从哪里来?
这部分信息必须公开,不公开谁知道是不是默认呢? 我在哪里可以看到结果?
王思聪的获奖帖子他的微博上肯定有条目抽奖html,所以去微博首页搜索“王思聪”。
然后我点进去就到了他的微博主页。 从最近的帖子中,我看到了他发布的一条关于抽奖结果的消息,上面有一个列表公告链接。
点击这个链接,果然,我看到了所有彩票中奖者的名单:
点击第一个看到,到了他的微博主页,而且没有性别,虽然头像上有一个箭头,不太直观。 继续观察,看到右下角有一个“查看更多”
点进去一看,基本可以看到公开的信息。
好了,到目前为止,我们已经研究了查找彩票列表的详细信息路径,下面就是如何统计这些信息。
113、自动统计? 太多麻烦了!
编程? 门槛太高了!
有没有什么工具可以帮助我们呢? 有!
废话不多说,我们直接上步骤吧!
使用软件:网络爬虫
安装步骤,观看视频:
安装完成后,打开webscraper并点击“导入站点地图”
下面需要用到的一些代码的含义就不用关注了。
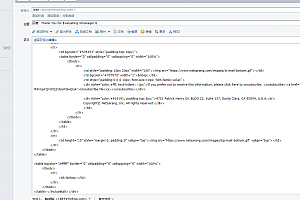
{"_id": "wangsicong","startUrl":["http://event.weibo.com/yae/event/lottery/result?pageid=100140E1198435&id=3436763&f=weibo"],"selectors":[{" id":"people","type":"SelectorElementClick","parentSelectors":["_root"],"selector":"h4a.S_txt1","multiple":true,"delay":"2000"," clickElementSelector":"a.page.S_txt1:nth-of-type(n+3)","clickType":"clickOnce","discardInitialElements":false,"clickElementUniquenessType":"uniqueText"},{"id": "bbb","type":"SelectorLink","parentSelectors":["people"],"selector":"_parent_","multiple":false,"delay":0},{"id":"ccc ","type":"SelectorLink","parentSelectors":["bbb"],"selector":"div.
PCD_person_infoa。 WB_cardmore","multiple":false,"delay":"2000"},{"id":"ddd","type":"SelectorElement","parentSelectors":["ccc"],"selector":" div#plc_main","multiple":false,"delay":"3000"},{"id":"eee","type":"SelectorText","parentSelectors":["ddd"],"选择器" :“div。 WB_cardwrap:第 n 个类型 (1)li。 li_1:第 n 个类型 (1) 跨度。 pt_detail","multiple":false,"regex":"","delay":0},{"id":"address","type":"SelectorText","parentSelectors":["ddd"], “选择器”:“李。 li_1:第 n 个类型 (2) 跨度。 pt_detail","multiple":false,"regex":"","delay":0},{"id":"sex","type":"SelectorText","parentSelectors":["ddd"], “选择器”:“李。
li_1:第 n 个类型 (3) 跨度。 pt_detail","multiple":false,"regex":"","delay":0},{"id":"时间","type":"SelectorText","parentSelectors":["ddd"], “选择器”:“李。 li_1:第 n 个类型(7)跨度。 pt_detail","multiple":false,"regex":"","delay":0},{"id":"following","type":"SelectorText","parentSelectors":["ddd"], “选择器”:“td。 S_line1:第 n 个类型 (1) 强。 W_f18","multiple":false,"regex":"","delay":0},{"id":"followed","type":"SelectorText","parentSelectors":["ddd"], “选择器”:“td。 S_line1:第 n 个类型 (2) 强。 W_f18","multiple":false,"regex":"","delay":0},{"id":"content","type":"SelectorText","parentSelectors":["ddd"], “选择器”:“td。
S_line1:第 n 个类型 (3) 强。 W_f18","multiple":false,"regex":"","delay":0},{"id":"level","type":"SelectorText","parentSelectors":["ddd"], “选择器”:“p。 level_infospan。 信息:第 n 个类型 (1) 跨度。 S_txt1","multiple":false,"regex":"","delay":0},{"id":"vip","type":"SelectorText","parentSelectors":["ddd"], “选择器”:“p。 信息:nth-of-type(2)","multiple":false,"regex":"","delay":0},{"id":"生日","type":"SelectorText","父选择器":["ddd"],"选择器":"li. li_1:第 n 个类型 (4) 跨度。 pt_detail","multiple":false,"regex":"","delay":0}]}
需要输入2条信息:
1.逐字复制并粘贴。 如果有错误信息,请逐字检查是否正确。 逐字逐句意味着单个标点符号不能有偏差。
2.英文字母,随意书写。
填写完毕后,点击下面的“导入站点地图”。
之后,点击中间的下拉菜单,点击“抓取”
之后,点击“开始抓取”
之后会弹出一个窗口,你要做的就是——等,等他抢完。
这时,你可以在笔记本上做任何其他事情,只是不要关闭这个弹出窗口。
大约需要 10-20 分钟才能完成捕获。 具体时间根据具体情况而定。 捕获后,手动关闭窗口。
之后你会看到下图,点击“刷新”。
出现大量数据后,点击中间菜单栏,点击“将数据导出为CSV”。
点击“下载”。
好的抽奖html,捕获的数据已经下载到笔记本中了,你可以用excel打开,看看里面有什么?
可以看到113条数据,即113个抽奖名单,包括昵称、地点、性别、注册日期、关注者、粉丝数、发帖数、微博级别、会员级别、个性化签名等。
也许你听到的和里面的截图会有些不同。 由于我已经删除了不相关的信息栏目,所以你就直接下载了,没有删除。 你可以研究一下这些冗余数据是什么? 不过很有趣!
我们可以清楚地看到,性别一栏不仅只有一名男性,其他都是女性。 我们的目的已经达到了,是不是可以看起来更漂亮呢?
据说excel中的数据透视表可以做出一个看起来非常好看的图表,而数据透视表听起来却很难。 其实我只花了1分钟,然后我发现我没有学会,所以我放弃了。
我心里有一个声音,一定有更简单的方法可以做到这一点,一定有!
然后我开始沉思,果然,突然,我想到了Microsoft Sheets,(也许我尝试了很多工具,发现Microsoft Sheets是最好的),应该可以做到这一点。
快速打开Microsoft,搜索“Google Sheets”,点击第一个网站,先创建一个空白表单。
之后,只需粘贴先要处理的数据即可。 我将性别列数据粘贴到新建的空白表中,如下——
我认为微软的产品简单、易于操作。 当我选择要处理的列时,应该有一个按钮。 一旦我按下它,它就会手动为我生成一个图标。 嗯,一定是这样的。
谁在乎! 我命令! 观点! 观点……
果然,在插入菜单下,我找到了一个叫做“图表”的选项——
没关系,先看看疗效——
哈哈,是的,确实有效!
不过这些显示比例的数据,我之前看过别人的图片,似乎还是用圆饼比较舒服。 应该有一个按钮来选择图表类型。 算了,试试吧!
果然,右边找到了一个选项! 正是我想要的饼图。
谁在乎,点击试试——
完美的!
Excel上还有其他类型的数据,我们把它们放在一起做一个图表。 总之,图标类型这么多,都尝试一下,选一个看起来漂亮的吧!
区域
广州、北京、广东人数最多,似乎符合预期。