▲点击上方卡片关注,您的关注是我继续更新优质文章的动力。
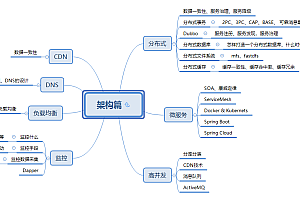
1 功能说明
这是一个基于小红书陌陌小程序的爬虫,实现了小红书的关键词搜索记录。
2 疗效示范记录
这是一个用python制作的爬虫程序。
运行代码,
输入您要搜索的关键字。
它可以抓取5个页面,每页20条,总共100条与关键词对应的笔记/视频数据。
ps:由于小程序限制,最多只能获取5页数据。 目前还没有找到更好的办法。
3 实现这个想法并这样做的原因

最近在研究python爬虫。 我也在跑小红书,我是一个小up。
自己做图笔记的时候,想想怎么做,这样才能获得更多的“小眼睛”(观看量),获得更多的点赞、收藏、评论。
为此,我会利用小红书的搜索功能来搜索和我同类型的笔记,看看热门笔记是如何设计笔记标题和封面的。
然而,手动搜索效率太低。
我想知道是否可以编写一个程序来帮助我收集我想要的数据。
这就是做这个程序的想法。
既然是基于小红书里的关键词搜索,我的第一个想法就是解决一个问题。
如何直接获取搜索功能的相关socket。
如果找到这个socket,批量获取数据就方便了。
开始寻找插座

寻找插座经历了很多困难。
我在百度和谷歌上搜索了一下,发现小红书里的数据是网上最难爬的。
即使你在github上搜索,也找不到任何可以直接运行的代码。
很多知名网站都有网页端,搜索功能也不隐藏。 所以收集数据相对容易。
但小红书在网页端无法直接找到可搜索的入口小红书网站爬虫程序,所以无从下手。
在错误的道路上越走越远
这使得我一开始只能尝试从小红书app上寻找突破口。
根据我的了解,我安装并尝试了很多抓包软件。 不限于Fiddler、Charles等。
最终我发现Fiddler更方便,所以我还是用了Fiddler。
错误的道路:
1. Fiddler窃听小红书app
打开并配置Fiddler,让手机通过Wlan连接到与笔记本相同的局域网,并将Wlan代理设置为笔记本ip地址的指定端口。 端口号是在Fiddler中配置的。
然后使用Fiddler查看拦截到的小红书app的数据请求信息。
期间我在手机上安装了Fiddler的需要SSL许可证的CA证书,让手机可以信任Fiddler发起的流量转发。
配置完后发现手机需要root,并且需要安装Xposed框架才能安装JustTrustMe插件。
这条路被堵住了,宣告失败。
2. 尝试绕过系统
首先,我的手机一定不能root,而且因为是华为鸿蒙3.0,如果强行root的话,可能会变砖,所以我不敢冒这个风险。
所以没有尝试root。
很巧的是,我发现可以选择安装星易,这样就可以不用root就享受su权限,安装Xpose插件。

天真的我,安装了Xposed和Xposed插件后。
发现Fiddler窃听小红书App,App会直接提示无网络、系统时间错误。
这条路被堵住了,宣告失败。
3.安装Android虚拟机
幸运的是,我发现可以安装Android虚拟机。
我在虚拟机中虚拟了一台root过的机器,然后安装了星易、插件、小红书。
运行Fiddler来监控小红书app。
但小红书app会崩溃。
这条路被堵住了,宣告失败。
4、电脑上安装手机模拟器

我继续走在这条路上。 知道可以在笔记本上安装一个手机模拟器,然后按照上面的解决方法进行安装。
我没有执行这个计划。 我一直认为我选择的方向是错误的。
这条路我不能再继续下去了,太糟糕了。
返回并寻找其他解决方案。
找到正确的方向
回过头来继续寻找解决方案,发现很多成功的案例都需要用到全能的陌陌小程序。
张小龙,你是我的神。
据了解小红书网站爬虫程序,小红书的陌陌小程序有简单的关键词搜索功能。
这就够了。
去做就对了。
开始配置Fiddler来窃听Momo小程序的数据流。
这段时间我发现小红书的域名数据可以抓取,但是我能理解的只是小红书的图片资源。
这篇实用文章由微博低代码布道者陈玉明提供。
腾讯云Microbuild是一个拖拽式低代码开发平台,无需代码编译,构建者可以完全专注于业务场景。 微构建低代码以云开发为底层支撑,云原生能力打通应用构建的全链路,提供高度开放的开发环境。
产品架构图
WeTake提供三个月免费试用,后续收费。 对于开发者来说,后续的每月9.9基础资源包就足够了。
进入微构建控制台:
接下来我会通过一个收集信息的小程序案例来讲解微构建:
构建微构建与编写小程序不同。 对于小程序来说,是先页面然后数据,而微构建则是先数据然后页面。 第一步是数据源的管理。 数据管理本质上就是云端开发的CMS内容管理。
构建数据源
它分为两页
首先选择数据源。
创建新的数据源本质上就是创建一个新的数据库。
数据名称默认按照拼音首字母标注。
生成完毕后,开始设置数据源数组源码网站程序带采集,本质就是设置表结构。
添加数组。
添加完成后,点击确定返回数据源列表,选择当前数据源,点击更多选择管理数据。
然后就会进入内容管理后台。 在内容管理后台,有两种数据管理,一种是发布版本,一种是预览版本。
页面构建
然后进入构建小程序页面,切换到低代码菜单页面,选择应用菜单。
选择从空白页新建。
选择一个小程序。
输入名称源码网站程序带采集,步入后会提示创建新页面。选择空白页面。
选择表单容器。
选择表单容器设置表单场景-添加新记录。
选择绑定刚刚创建的数据源——创建一条记录。

选择完成后,会提示是否手动生成表单组件。
这就是为什么我需要首先创建一个数据源。 可以根据数据源上数据的格式手动生成表单组件。
如果您对手动生成的组件样式不满意,可以选择需要调整的组件,然后在左侧属性面板中更改样式。
表单生成后,可以点击上面的预览进行测试。
如果测试时输入了错误的手机号码,则会进行手动校准,这与创建数组时选择的数据类型有关。
当数据成功后,您可以在内容管理后台的预览环境中看到具体的管理和管理数据。
另外,还可以通过后台管理数据,采集页面已经完成。

要创建新的列表页面,请单击左上角的+号。
首先添加一个容器组件作为最里面的布局。
然后选择一个列表项并将其放置在容器上。 当组件就位后,您可以连接到数据源。
第一步是单击左上角创建一个新的数据变量。
选择心理数据变量,选择模型变量。
选择数据源和查询方式。
单击保存列表变量,容器即可访问该变量。

拿出来开始绑定数据的属性,先选择容器,然后选择循环。
选择列表数据源。
连接它来显示列表中的具体值,选择列表项组件,找到标题绑定数据。
选择循环对象后,选择要显示的属性。
疗效如下:
显示数据库中的数据,后续数组操作同上。 它还可以呈现给其他组件。 请注意,所有循环都需要拖放普通容器。
如果你觉得通过属性栏直观地设置样式很麻烦,可以通过代码设置样式:
简单的展示需求和简单的增删改查逻辑都可以通过拖拽来实现,并且需要编译一些代码来变得更加灵活。