为什么需要模块化
场景1
同事A开发了模块a,同事B开发了模块b,通过以下方法在页面下引用
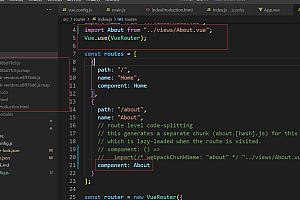
此时,如果模块a中定义了方法del,则模块a和模板b中的代码都暴露到全局环境中。 朋友b不知道模块b中也定义了一个del方法。 这时候就出现了命名冲突的问题。如图
场景2
朋友C开发了一个公共工具库utils.js,朋友D开发了一个公共组件tab.js,tab.js依赖于utils.js。朋友E需要使用朋友D开发的tab.js,所以他需要使用以下方法可供参考
朋友E也开发了一个dailog.js,它也依赖于util.js。 当前页面同时引用dialog.js和tab.js,代码如下。
E朋友除了需要同时引用这三个js文件外,还必须保证文件之间的引用顺序正确。 同时webpack常用的模块,从前面的代码中,我们很难直接看到模块之间的依赖关系。 如果我们不深入 tab.js,我们无法知道 tab.js 是只依赖于 util.js 还是dialog.js 或者两者都依赖。 依靠。 随着项目逐渐缩小webpack常用的模块,不同模块之间的依赖关系会变得越来越难以维护,很多模块中的大量变量会暴露到全局环境中。
模块化的几种实现方案
模块化规格有多种,如下
|规范|实施方案|
|---|---|
|CommonJS|node.js|
|AMD|Require.js|
|CMD|Sea.js
|UMD||
|ES6模块||
webpack 支持 CommonJS、AMD、ESModule 等模块化句型。
webpack的模块化原理
在 webpack 中,一切都是模块。 下面我们使用webpack来打包以下代码。 通过对打包代码的分析,让我们一步步了解模块化的原理。
目录结构如下:
代码如下所示:
// webpack.config.jsconst path = require('path');module.exports = {entry: 'a.js',output: {path: path.resolve(__dirname, "dist"),filename: "[name].js"},resolve: {modules: [path.resolve(__dirname)]},optimization: {minimize: false}}// a.jsvar b = require('b');module.exports = b.text + ' world';// b.jsexports.text = 'hello';在simple目录下执行webpack命令,会在simple目录下生成dist/output.js文件。
// outout.js// 代码及注释如下(() => {// 所有导入的模块都存储在__webpack_modules__对象中,并且每个模块都要一个标识该模块的idvar __webpack_modules__ = ({847: ((module, __unsed_webpack_exports, __webpack_require__) => {// 模块a...}),996: ((__unused_webpack_module, exports) => {// 模块b...})})var __webpack_module_cache__ = {};function __webpack_require__(moduleId) {// 检查缓存中不存在847导出对象,防止模块847多次执行if (__webpack_module_cache__[moduleId]) {// 从缓存中返回847导出对象return __webpack_module_cache__[moduleId].exports;}// 1.创建{exports: {}}对象// 2.像缓存中添加该对象,并让该对象与模块id 847相关联var module = __webpack_module_cache__[moduleId] = {exports: {}}// 3.通过__webpack_modules__查询模块847// 4.执行模块847并传入刚刚创建的模块847的导出对象module,以及module.exports等__webpack_modules__[moduleId](module, module.exports, __webpack_require__);// 5.返回模块847的导出对象return module.exports;}// 导入模块847__webpack_require__(847);})()从上面的代码我们可以知道,所有模块都存储在__webpack_modules__对象中,模块的导入对象存储在__webpack_module_cache__对象中。 我们定义的模块可以通过调用 __webpack_require__ 套接字来访问,传入 moduleId 模块和模块的导入对象。
当我们通过__webpack_require__套接字访问模块847的导入对象时。 首先会判断__webpack_module_cache__对象中是否存在该模块的import对象,如果有则直接返回,如果没有则将
(1)创建847模块的导入对象
var module = {exports: {}}(2)将导入对象添加到__webpack_module_cache__对象中
__webpack_module_cahce__[moduleId] = module(3)(4)通过__webpack_modules__查询模块847并执行
// 传入模块847的导出对象,以及require接口__webpack_modules__[moduleId](module, module.exports, __webpack_require__)(5)返回模块847的导入对象
return module.exports示意图如下:
橙色背景的元素代表数据
红色背景的元素代表函数
总结
通过模块化的管理方法
每个模块都通过函数封装在自己的本地环境中。 模块之间通过 require 套接字进行通信。 并且无需将其暴露在全球环境中。
每个模块通过require套接字明确导入依赖的模块,因此模块之间的依赖关系也非常清晰。 如图a->b->c->d
当模块第一次被引用时,调用require套接字会将导入对象添加到缓存中。 并返回添加的导入对象。
当模块被第2次引用时,调用require套接字查询缓存对象时,返回缓存中对应的导入对象。
这篇文章就结束了~
webpack_require的逻辑写得很清楚了。 首先检查模块是否已经加载,如果是,则直接从Cache中返回模块的导出结果。 如果是全新的模块,那么完善对应的数据结构模块,但是运行这个模块的generatecode,这个函数传入的是我们构建的模块对象和它的exports字段,这其实就是exports和exports的由来模块。 当这个函数运行时,模块被加载,需要导出的结果被保存在模块对象中。
所以我们看到所谓的模块管理系统,原理看似很简单,只要耐心梳理一下,没有什么高深的东西可言,就是由这三部分组成:
//所有模块的生成代码 varmodules; //所有已经加载的模块,作为缓存表 varinstalledModules; //加载模块的函数 functionwebpack_require(moduleId);
其实上面所有的代码都被包裹在一个大的匿名函数中,在整个编译好的bundle文件中立即执行,最终返回的是这句话:
return webpack_require('./app.js');
也就是说,当入口模块app.js加载时,之前的所有依赖都会在运行时动态递归加载。 事实上,Webpack 实际生成的代码略有不同,其结构大致是这样的:
(function(modules){variinstalledModules={};functionwebpack_require(moduleId){//...}returnwebpack_require('./app.js');})({'./mA.js': generated_mA,'./ app.js': generated_app});
可以看到,它直接将模块作为立即执行函数的参数传递,而不是单独定义它们。 其实这和里面写的并没有本质的区别。 我重写是为了更清楚地解释它。
ES6导入导出
在上面的例子中,使用了传统的 CommonJS 风格。 现在比较常见的ES6风格使用的是import和export关键字,用法也略有不同。 然而,对于Webpack或其他模块管理系统来说,这个新功能应该只被视为语法糖,它们本质上与require/exports相同,例如export:
exportaa //相当于: module.exports['aa']=aaexportdefaultbb //相当于: module.exports['default']=bb
对于进口:
import{aa}from'./mA.js'//相当于varaa=require('./mA.js')['aa']
比较特别的是这个:
从'./m.js'导入m
情况会复杂一点,它需要加载模块m的defaultexport,而模块m可能不是ES6导出写的,也可能根本没有exportdefault,所以当Webpack为模块生成generatecode时,会判断它不是 ES6 风格的导出。 例如,我们定义模块 mB.js:
letx=3;letprintX=()=>{console.log('x='+x);}export{printX}exportdefaultx
它使用了ES6的export,所以Webpack会在mB的generatecode中添加一句:
function generated_mB(module,exports,webpack_require){Object.defineProperty(module.exports,'__esModule',{value:true});//mB的具体代码//....}
换句话说,它为mB的导出标记了一个__esModule,表明它是ES6风格的导出。 这样,在其他模块中,当以 importmfrom './m.js' 的形式加载依赖模块时,会首先判断是否是 ES6 导出的模块。 如果是,则返回其默认值,如果不是,则返回整个导出对象。 比如前面的mA是传统的CommonJS,mB是ES6风格:
//mAisCommonJSmoduleimportmAfrom'./mA.js'console.log(mA);//mBisES6moduleimportmBfrom'./mB.js'console.log(mB);
我们定义 get_export_default 函数:
函数 get_export_default(module){returnmodule&&module.__esModule?module['default']:module;}
这样,生成的代码运行后,在 mA 和 mB 上会得到不同的结果:
varmA_imported_module=webpack_require('./mA.js');//复制完整的mA_imported_module console.log(get_export_default(mA_imported_module));varmB_imported_module=webpack_require('./mB.js');//复制mB_imported_module['default' ] console.log(get_export_default(mB_imported_module));
这是 Webpack 需要对 ES6 导入进行一些特殊处理的地方。 但总的来说,ES6 的 import/export 本质上和 CommonJS 是一样的,只不过 Webpack 生成的代码仍然是基于 CommonJS 的 module/exports 机制来实现模块的加载。
模块管理系统
以上就是Webpack如何打包组织模块并实现运行时模块加载的分析。 虽然其原理并不难,但核心思想是构建模块管理系统,而且这种做法也是通用的。 如果你看过 Node.js 中 Module 部分的源码,似乎也使用了类似的方法。 这里有一篇文章可供参考。
如今,后端使用Webpack打包JS等文件已经是主流。 再加上Node的流行,后端的工程方法和前端越来越相似。 最后一切都被模块化并统一编译。 由于Webpack版本的不断更新以及各种错综复杂的配置选项,使用中一些令人困惑的错误常常让人感到不知所措。 所以了解Webpack如何组织和编译模块,以及生成的代码如何执行是很有用的,否则它永远是一个黑匣子。 其实我是一个后端新手,最近才开始研究Webpack的原理,所以在这里做一点记录。
编译模块
编译这两个字听起来很黑科技,而且生成的代码往往是一大堆看不懂的东西,所以常常让人感叹,但毕竟上面的核心原理并不难。 所谓Webpack编译只是Webpack在分析你的源代码之后进行一定的更改,然后将所有源代码组织在一个文件中。 最后生成一个大的bundleJS文件,由浏览器或其他Javascript引擎执行并返回结果。
这里用一个简单的案例来说明Webpack打包模块的原理。 例如我们有一个模块 mA.js
varaa=1;functiongetDate(){returnnewDate();}module.exports={aa:aa,getDate:getDate}
我随意定义了一个变量aa和一个函数getDate,然后导出。 下面是CommonJS的写法。
然后定义一个app.js作为主文件,一直是CommonJS风格:
varmA=require('./mA.js');console.log('mA.aa='+mA.aa);mA.getDate();
现在我们有两个模块,它们是用Webpack打包的。 入口文件为app.js,依赖于mA.js模块。 Webpack 需要做几件事:
从入口模块app.js开始,分析所有模块的依赖关系,读取所有用到的模块。
每个模块的源代码被组织成立即执行的函数。
重写模块代码中require、export相关的句型,及其对应的引用变量。
只有在最终生成的bundle文件中构建模块管理系统,才能在运行时动态加载所使用的模块。
我们可以看一下前面的反例,Webpack打包的结果。 最终的捆绑文件通常是一个立即执行的大函数。 组织层次比较复杂,大量的名字也比较冗长,所以我在这里重新编写和修改,使其尽可能简单易懂。
首先是列出所有使用的模块webpack原理,并使用它们的文件名(通常是完整路径)作为 ID 来建表:
varmodules={'./mA.js': generated_mA,'./app.js': generated_app}
关键是里面的generate_xxx是什么? 它是一个函数,将每个模块的源代码包装在其上,使其成为局部作用域,这样内部变量就不会暴露出来,它实际上将每个模块变成了一个执行函数。 它通常是这样定义的:
function generated_module(module,exports,webpack_require){//模块的具体代码。 //...}
这里模块的具体代码指的是生成的代码,Webpack 称之为 generatedcode。 如mAwebpack原理,重写后结果为:
function generated_mA(模块,exports,webpack_require){varaa=1;functiongetDate(){returnnewDate();}module.exports={aa:aa,getDate:getDate}}
乍一看,它与源代码一模一样。 确实,mA 不需要或导入其他模块,并且导出使用传统的 CommonJS 风格,因此生成的代码没有任何变化。 不过值得注意的是最后一个module.exports=...,这里的module是从外部传入的参数module,它实际上告诉我们,当这个函数运行的时候,模块mA的源代码将会是执行了,但是最终需要将export的内容保存到外部,这就标志着mA加载完成,而那种外部的东西其实就是前面提到的模块管理系统。
接下来看app.js的生成代码:
function generated_app(module,exports,webpack_require){varmA_imported_module=webpack_require('./mA.js');console.log('mA.aa='+mA_imported_module['aa']);mA_imported_module['getDate'](); }
可以看到app.js源码中导入模块mA的部分被改动了,因为无论是require/exports还是ES6风格的import/export都不能被JavaScript协程直接执行,它需要依赖模块管理系统将这些具体关键字具体化。 也就是说,webpack_require是require的具体实现,它也可以动态加载模块mA,并将结果返回给app。
至此,你的脑海中可能已经逐渐建立起了一个模块管理体系。 我们看一下webpack_require的实现:
//加载所有模块。 varinstalledModules={};functionwebpack_require(moduleId){//如果模块已经加载,则直接从Cache中读取。 if(installedModules[moduleId]){returninstalledModules[moduleId].exports;}//创建一个新模块并将其添加到installedModules中。 varmodule=installedModules[moduleId]={id:moduleId,exports:{}};//加载模块,即运行模块生成的代码,modules[moduleId].call(module.exports,module,module.导出,webpack_require); 返回模块。 出口; }
请注意,倒数第二句中的模块是我们之前定义的所有模块的生成代码:
varmodules={'./mA.js': generated_mA,'./app.js': generated_app}