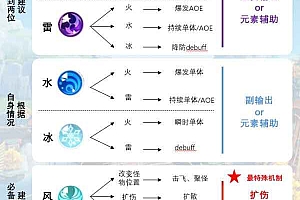
爆炸性性能的记忆队列!!
干扰
是一个相对小众的知识点,但如果你在项目经验中使用Disruptor,你可能会在笔试中被问到。
本文可以看作是对Disruptor的简单总结,每个问题都不会太深入,主要是为了笔试或者快速浏览Disruptor。
什么是颠覆者?
Disruptor是一个开源的高性能内存队列,为解决内存队列的性能和内存安全问题而诞生,由美国外汇交易公司LMAX开发。根据Disruptor
官方介绍,基于Disruptor开发的系统LMAX(新零售金融交易平台),单个线程每秒可支持600万个订单。Martin Fowler在2011年的TheLMAXArchitecture [1]上写了一篇文章,专门介绍了这个LMAX系统的架构。
在LMAX的2010年QCon演讲之后,Disruptor获得了业界的关注,并于2011年获得了甲骨文官方的杜克选择奖。
杜克选择奖旨在表彰过去一年中由世界各地的个人或公司开发的最具影响力的Java技术应用程序,由Oracle主办。含金量特别高!
我特别找到了甲骨文正式实施的赢得杜克选择奖计划的文章(文章地址:)。从文章中可以看出,同年获得此殊荣的还有著名的Netty、JRebel等项目。
2011年甲骨文官方公爵选择奖
Disruptor提供的功能优势类似于分布式队列,如Kafka和RocketMQ,但其范围是JVM(视频内存)。
为什么要使用颠覆者?
中断器主要解决JDK外部线程安全队列的性能和内存安全问题。
JDK 中常见的线程安全队列如下所示:
队列名称子锁是否具有有界边界
ArrayBlockingQueue
可重入锁定
界
链接阻塞队列
可重入锁定
界
链接传输队列
无锁定 (CAS)。
无限
ConcurrentLinkedQueue
无锁定 (CAS)。
无限
从上表可以看出,这种队列要么是锁定和有界的,要么是解锁和无界的。锁定队列势必影响性能,未绑定队列存在内存溢出的风险。
因此,通常不建议使用 JDK 外部线程安全队列。
颠覆者是不同的!它保证有界队列没有锁,并且是线程安全的。
下图是Disruptor官方网站提供的Disruptor和ArrayBlockingQueue的延迟直方图的比较。
中断器延迟直方图
Disruptor真的很快html缓存,为什么它这么快的问题将在后面介绍。
据悉,Disruptor还提供了丰富的扩展功能,例如支持批量操作,支持多种等待策略。
Kafka和Disruptor有什么区别?哪些组件使用中断器?
那里
是相当多使用Disruptor的开源项目,这里有一些反例:
颠覆者的核心概念是什么?
下图取自 Disruptor 网站,显示了使用 Disruptor 的 LMAX 系统示例。
什么
是使用中断器的 LMAX 系统的中断器等待策略的示例?等待
策略:确定消费者在没有风暴可消费的情况下如何等待新风暴的到来。
常见的等待策略如下:
干扰
等待策略为什么颠覆者这么快?
综上所述,Disruptor之所以能够如此之快,是基于一系列优化策略的综合效果,既充分利用了现代CPU缓存结构的特点,又消除了常见的并发问题和性能困境。
有关中断器高性能队列原理的详细介绍,可以查看本文:讨论中断器高性能队列的
原理[2](参考美团技术团队的高性能队列-中断器[3]文章)。
这里有一个额外的说明:为什么字段中的连续对象元素地址会提高性能?
CPU 缓存通过将最近使用的数据存储在缓存中来实现更快的读取速率html缓存,并使用预取机制更早地从相邻视频内存加载数据以利用局部性原则。
在计算机系统中,CPU主要访问缓存和视频内存。缓存是一种速率非常快、容量相对较小的视频内存,一般分为多级缓存,其中L1、L2、L3分别代表一级缓存、二级缓存和三级缓存。越靠近 CPU 的缓存,速率越快,容量越小。相比之下,内存容量相对较大,但速率较慢。
CPU 缓存模型图
为了加快数据读取过程,CPU会先将数据从显存加载到缓存中,如果下次需要访问相同的数据,可以直接从缓存中读取,而不必再次访问显存。这称为缓存命中。此外,为了利用局部性原则,CPU会根据之前访问的内存地址预取相邻的内存数据,因为在程序中,连续的内存地址一般会被频繁访问,这样可以提高数据的缓存命中率,从而提高程序的性能。
引用
[1]
LMAXArchitecture:
[2]
中断器高性能排队原理讨论:
[3]
高性能队列 – 中断者:
传智教育黑马程序员
所有学科都在如火如荼地进行
基础班28元
浏览器厂商和开发者共同努力的方向之一就是让网站变得更快。 著名的加速方案有很多:CSS精灵(CSS sprites、拼图)和图像优化、分布式配置文件(.htaccess)、JS/文本文件压缩、CDN加速等。
我在另一篇博文中介绍了如何使您的网站更快。
FireFox引入了一种新的网站加速策略:链接预加载。 什么是链接预加载? MDN是这样描述的:

[清楚的]

预加载是一种浏览器机制,它利用浏览器空闲时间来预下载/加载用户接下来可能浏览的页面/资源。 该页面向浏览器提供了需要预加载的集合。 浏览器加载完当前页面后html 加载,会在后台下载需要预加载的页面,并将其添加到缓存中。 当用户访问预加载的链接时,如果从缓存中命中,则可以快速呈现页面。

预加载是一种浏览器机制,它利用浏览器空闲时间来预下载/加载用户接下来可能浏览的页面/资源。 该页面向浏览器提供了需要预加载的集合。 浏览器加载完当前页面后,会在后台下载需要预加载的页面,并将其添加到缓存中。 当用户访问预加载的链接时,如果从缓存中命中html 加载,则可以快速呈现页面。

简要概述:网站根据用户进行分析,浏览器在后台下载指定的页面/文档/图片,超级容易实现:

HTML5 预加载标签
[html]
从前面的HTML代码可以看出,预加载使用标签并指定属性,而href属性就是需要预加载的文件路径。 Mozilla 也实现了一些类似的 link rel 属性:
[html]