陌公众号认证完成后,就可以对用户的消息做点什么了。(请参阅消息类型开发文档)。
这
用户与公众号之间的消息交互类型分为文字、图片、语音、视频、小视频、地理位置、链接等。用户
消息被传输到我们用XML构建的服务器,我们需要解析XML信息,获取所需的信息,处理后回复用户。
让我们简要看一下文本消息和图像消息的 XML 结构。
发短信:
1348831860 1234567890123456
图像:
1348831860 1234567890123456
可以看出,两者共有的数组是 ToUserName、FromUserName、CreateTime、MsgType 和 MsgId,对于文本消息,我们可以直接通过 Content 数组提取消息文本内容,而对于图片消息,我们需要通过 PicUrl 或 MediaId 获取图片信息并进行处理。
以下是Python公众号开发部分代码开源-学习编程-知乎栏目给出的一种编写方法:
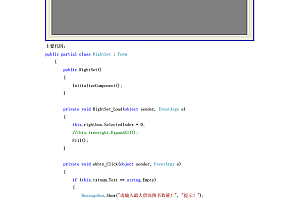
def POST(self): str_xml = web.data() #获得post来的数据 xml = etree.fromstring(str_xml)#进行XML解析 content=xml.find("Content").text#获得用户所输入的内容 msgType=xml.find("MsgType").text fromUser=xml.find("FromUserName").text toUser=xml.find("ToUserName").text if(content == u"天气"): pass
我不推荐这些文字,因为在那篇文章中,笔者只处理了短信,并没有实现消息类型的相应判断,这时如果服务器收到图片消息,content=xml.find(“Content”).text将无法执行,返回错误信息,导致公众号无法正常工作, 所以最好先写消息类型,然后再执行相应的操作。
def POST(self): str_xml = web.data() #获得post来的数据 xml = etree.fromstring(str_xml)#进行XML解析 msgType=xml.find("MsgType").text fromUser=xml.find("FromUserName").text toUser=xml.find("ToUserName").text if msgType == 'text': content=xml.find("Content").text if(content == u"天气"): pass elif msgType == 'image': pass else: pass
收到用户发送的消息后,我们
需要考虑如何向用户发送消息,看起来并不难,我们只需要给出一个消息模板并在对应函数的末尾设置返回值即可
return self.render.reply_text(fromUser,toUser,int(time.time()), 'you string here')
在目录中创建新模板/reply_text.xml
$def with (toUser,fromUser,createTime,content) $createTime
之后编辑 weixinInterface.py
def POST(self): str_xml = web.data() #获得post来的数据 xml = etree.fromstring(str_xml)#进行XML解析 msgType=xml.find("MsgType").text fromUser=xml.find("FromUserName").text toUser=xml.find("ToUserName").text if msgType == 'text': content=xml.find("Content").text return self.render.reply_text(fromUser,toUser,int(time.time()), content) elif msgType == 'image': pass else: pass
上述操作的作用是:确定用户消息类型,如果消息类型为文本,则获取其内容内容,并以原始外观将内容作为消息返回。
完成上述更改后,重复 git 操作,将更改推送到远程仓库。
git add . git commit -m 'your commit message' git push sae master:1
测试效果图:
2.3 短信操作示例——检查快递
在上一节中,我们已经完成了短信最基本的操作,并按原样返回内容,并没有再做任何操作,这次我们将尝试快速套接字。
我仍然
在上面提到的文章中使用了快的100 Check快速套接字,但是我在本地测试了很多次,SAE服务器仍然无法返回正常结果,上网搜索了很长时间后,发现Express 100屏蔽了SAEIP段的请求,哪个套接字无法使用, 代码也被销毁了。所以我们只能退居第二位,做一个功能,通过快递跟踪号来判断快递公司。
仍然 weixinInterface.py 改变
def POST(self): str_xml = web.data() #获得post来的数据 xml = etree.fromstring(str_xml)#进行XML解析 msgType=xml.find("MsgType").text fromUser=xml.find("FromUserName").text toUser=xml.find("ToUserName").text if msgType == 'text': content=xml.find("Content").text if content[0:2] == u"快递": post = str(content[2:]) r = urllib2.urlopen('http://www.kuaidi100.com/autonumber/autoComNum?text='+post) h = r.read() k = eval(h) kuaidi = k["auto"][0]['comCode'] return self.render.reply_text(fromUser,toUser,int(time.time()), kuaidi) elif msgType == 'image': pass else: pass
前面
的函数很简单,就是判断如果用户消息的前两个字是快递的,取出前面的字符串作为快递跟踪号,通过套接字查询后将结果发送给用户。重复 git 命令更新远程代码后的测试效果图如下:
至此,我们已经完成了第一部分,服务器设置和一些简单的短信操作。虽然
对于一个有一定编程能力的男人来说,打破了这层阳台纸之后,虽然他可以根据自己的兴趣和经验做出很多自己喜欢的东西。享受编码!
3. 蜿蜒的小径通向僻静的地方
在完成对短信的一些基本操作后,我们可以尝试做一些更有趣的事情。之前说过,Python 公众号开发部分的代码开源——学习编程——知乎栏在源代码开头省略了 msgType 的判断,除了原作者还使用了极致的过程编写和极其臃肿的代码结构,这部分我们会尝试添加第三方依赖包, 尝试通过提取函数来构建代码,最后尝试处理图片消息。
3.1 添加第三方依赖包
在之前的套接字调用中,我们使用了 urllib2 库,熟悉 Python 爬虫的人都知道,虽然我们最常用的是第三方请求库,但如何将第三方库添加到 SAE 空间呢?看完开发文档,我得到了答案:#tian-家-地-三-方-一-来宝
具体方法不一定屈服于官方步骤,可以在本地仓库中创建新的文件夹供应商,然后使用 pip-t 选项指定第三方库安装地址,最后添加 index.wsgi 文件的路径。
以安装请求为例。
然后编辑 index.wsgi 并在底部添加代码。
# coding: UTF-8 import os import sae import web sae.add_vendor_dir('vendor') from weixinInterface import WeixinInterface
使用此第三方依赖项库,可以更轻松地实现所需的功能。
3.2 函数的结构
短信很多,如果我们不断添加判断,做一些操作并返回结果,代码势必看起来很臃肿,这不利于阅读,也不利于调试代码。因此,我们尝试将查询公司的现有代码通过跟踪号重写为一个函数。
创建新 cxkd.py
import urllib2 def detect_com(postid): r = urllib2.urlopen('http://www.kuaidi100.com/autonumber/autoComNum?text='+postid) h = r.read() k = eval(h) kuaiditpye = k["auto"][0]['comCode'] #print kuaiditpye return kuaiditpye
更改 weixinInterface.py,导出 cxkd.py 并更改源代码。
import cxkd def POST(self): str_xml = web.data() #获得post来的数据 xml = etree.fromstring(str_xml)#进行XML解析 msgType=xml.find("MsgType").text fromUser=xml.find("FromUserName").text toUser=xml.find("ToUserName").text if msgType == 'text': content=xml.find("Content").text if content[0:2] == u"快递": post = str(content[2:]) kuaidi = cxkd.detect_com(post) return self.render.reply_text(fromUser,toUser,int(time.time()), kuaidi) elif msgType == 'image': pass else: pass
经过测试,这些著作奏效了。其实在代码量大的情况下,这种编写方式可以使代码更加简洁易懂,从而改变调试。
3.3 旧罐装新酒——再谈人脸识别
在我长期的专栏(Python Crawler Notes (2):插话——我也会做 Facemash! - 一小段朋友的笔记 - 知乎专栏)之前提到过谷歌的 How-old.net 人脸识别插座,其实那种插座是我自己通过抢包收到的,那篇文章点赞不多,平时我好像看不出谁用那种插座实现了什么功能, 这次我想上去处理图片消息,我先想上去那种套接字。
老罐新酒,可以喝一杯什么都没有。
套接字的详细信息可以在上面的链接中查看,代码直接在这里给出。
创建新 imgtest.py
# -*- coding: utf-8 -*- import requests import re def imgtest(picurl): s = requests.session() url = 'http://how-old.net/Home/Analyze?isTest=False&source=&version=001' header = { 'Accept-Encoding':'gzip, deflate', 'User-Agent': "Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:34.0) Gecko/20100101 Firefox/34.0", 'Host': "how-old.net", 'Referer': "http://how-old.net/", 'X-Requested-With': "XMLHttpRequest" } data = {'file':s.get(picurl).content} #data = {'file': open(sid+'.jpg', 'rb')} #此处打开指定的jpg文件 r = s.post(url, files=data, headers=header) h = r.content i = h.replace('\','') #j = eval(i) gender = re.search(r'"gender": "(.*?)"rn', i) age = re.search(r'"age": (.*?),rn', i) if gender.group(1) == 'Male': gender1 = '男' else: gender1 = '女' #print gender1 #print age.group(1) datas = [gender1, age.group(1)] return datas
更改 weixinInterface.py
def POST(self): str_xml = web.data() #获得post来的数据 xml = etree.fromstring(str_xml)#进行XML解析 #content=xml.find("Content").text#获得用户所输入的内容 msgType=xml.find("MsgType").text fromUser=xml.find("FromUserName").text toUser=xml.find("ToUserName").text if msgType == 'image': try: picurl = xml.find('PicUrl').text datas = imgtest(picurl) return self.render.reply_text(fromUser, toUser, int(time.time()), '图中人物性别为'+datas[0]+'n'+'年龄为'+datas[1]) except: return self.render.reply_text(fromUser, toUser, int(time.time()), '识别失败,换张图片试试吧') else: content = xml.find("Content").text # 获得用户所输入的内容 if content[0:2] == u"快递": post = str(content[2:]) kuaidi = cxkd.detect_com(post) return self.render.reply_text(fromUser,toUser,int(time.time()), kuaidi) else: return self.render.reply_text(fromUser,toUser,int(time.time()), content)
然后将 Git 运送到远程仓库。测试如下:
4. 拉面红烧肉片
你分享玫瑰得到乐趣。
曾经有个同事问我,你为什么说要帮别人在网上完成一些任务,你是在伤害他们。
我
说不行单号网站源码,如何用Python编写脚本来捕获新浪财经网指定企业的报告? - 知乎用户的答案 当结果为空时,写出如何使用爬虫下载西安市环保局空气污染数据? - 知道用户的答案只给出了几个月的结果。虽然教是好事,但我自己就是一个学习的过程,如果能顺便帮助别人,自然是一件好事。
分享是一件有价值的事情。当初的知乎很不错,现在的知乎就不评价了。而且我还是愿意分享一些东西下来,虽然原来的成分可能不高,但可能全部放在一起,也可能很低,而这些都是我学到的一些经验,如果能让别人少走弯路,或者引起别人的兴趣,是一件很有功德的事情。
想了想,这次还是把代码都贴到了 Github 上,平时用的 Github 也不多,但怕复制粘贴知乎的编辑器会给你带来麻烦。
GitHub-loveQt/wxpytest
这次您还可以看到所有文档结构:(Chrome插件Octotree)。
最后,离开公众号
用在这个开发(红烧肉片寿司玫瑰趣),这是我个人公众号,做玩乐,关注不关注都无所谓,因为我平时不写东西单号网站源码,推东西。源代码已经粘贴,您可以根据文章在几分钟内构建一个相同的源代码。
今天的函数只有三块,更多的东西还没有添加:
1.回复快递xxxxxx手动识别快递公司
2.发送图片以识别性别和年龄
3. 其他文本信息以原始形式返回
(二维码手动识别)。
知乎增加了一个二维码进行人工识别。
网上有人出售仿天猫网站的源代码。 借助这段代码,可以生成一个与天猫网站布局非常相似的网站,甚至可以用“淘宝”二字丰富域名。
“钓鱼程序”卖家发送的模仿支付宝界面的程序截图。
网上购物诈骗调查 2

150元两小时“教包会”
新快报记者 张晓
足不出户,轻敲键盘即可购买从小戒指、耳环到大型车辆、房屋等各种商品。 网上购物已经成为越来越多的人的消费习惯。 而且,随之而来的骗局也越来越多——虚假宣传、错误商品、网络诈骗、“钓鱼”网站等,往往导致网购者无意中丢失赃物,并盗取身份证号、银行卡账户号码、密码等个人信息,后悔莫及。 我们将追查一个又一个网购骗局,破译网购“黑手”的盈利手段,为他人树立榜样。

欢迎向我们举报(邮箱:xkbjjxw@163.com 或新快报官方微博:)。
明天,新快报报道了吴晓梅在支付宝的2052元资金神秘失踪案。 关键问题是吴先生点击了非天猫网站链接。 “网站的页面和天猫一模一样,订购流程也一样。” 正是这个高度模拟的网站,让拥有七年多网购经验的吴女士绊倒了。 而记者明天在百度上搜索发现,输入关键词“钓鱼程序”,即可得到373万条搜索结果,其中大部分其实是公开兜售各种“钓鱼链接”、“钓鱼木马”的信息。 价格实惠,类似天猫的“钓鱼链接”低至150元即可购买。
“钓鱼程序”在网上随意出售

吴女士的遭遇是,虽然他首先登录了天猫网站,但点击了店铺提供的链接big5/t.taobao.com-1ewa.tk:81/t/item.htm/l。 asp?ai=46784,但这个富含淘宝字样的链接并非真正的天猫,因此支付宝也认为吴先生被“钓鱼”了。 经常网购的人都会听说过“钓鱼”,但大多数人并不知道小偷是如何“钓鱼”的。 在百度上,记者输入关键词“钓鱼程序”即可获得373万个链接网站钓鱼源码,发现大部分都是“钓鱼程序”的公开转发信息,其中“要发钓鱼程序”的网站位居第一。 记者点击其首页发现,该网站首页标明主营业务为“淘宝钓鱼程序”、“网络钓鱼程序”、“QQ钓鱼程序”、“钓鱼插件网站程序”。 记者以订购者身份联系了妖发工作室客服,对方以500元的价格提供了一套支付宝钓鱼方案。 对于通过这个程序能够看到对方支付宝账号和密码的问题,客服直接回复:“这不是废话吗?看不到账号再买也没用。”
不仅是“妖法”,有关转移钓鱼程序的信息已经遍布各个峰会和博客,就连曝光各种骗局的百度“骗局”贴吧也有有关转移“钓鱼链接”的帖子,而且价格甚至更高。 价格实惠。 记者通过QQ与销售岗位的联系人进行了交谈。 从天猫钓鱼程序到各种建行网站钓鱼程序都可以买到,价格一两百元也很实惠。 一位名叫海哥的“钓鱼程序”卖家告诉记者,他出售钓鱼链接和钓鱼木马。 链接只要200元,而木马则要1000元。 200元。” 经过记者多轮讨价还价,同时订阅天猫和建行财付通的钓鱼通仅需300元,海哥甚至表示自己还提供“钓鱼通”转租服务,月租150元。
该程序可以抓取财付通信息
150元买“钓鱼链接”能骗钱吗? 由于记者对网络不太熟悉网站钓鱼源码,担心订购这种“钓鱼程序”后,他询问了几家“钓鱼程序”卖家,但得到的答复都是“教育和会议,不要”。担心”。 “我教你网上操作,没问题的。” 上述“耀发工作室”客服告诉记者,“这个操作简单,购买一套后2小时内就能学会。” 为了说服记者,海哥还向记者发送了生成假支付宝界面的程序截图。 从截图中可以看出,小偷可以通过该程序完全设置天猫购物界面,包括宝贝的详细信息和产品的描述。 紧接着,记者还搜救出了一段笔记本程序高手本人在某网站制作钓鱼链接的解密视频。 该视频中使用了类似的程序,并且详细记录了操作的每一步。
“所谓‘淘宝钓鱼’,就是利用假冒的天猫网站,套取卖家的钱。卖家拿货付款后,钱直接到了买家之前搭建的平台,而不是通过支付宝支付。”第三方的,看起来和真正的天猫一模一样。” 视频制作人说道。 记者观看后发现,从在某网络游戏网站创建账号,到创建一个销售纸尿裤的假天猫页面(即“钓鱼链接”),然后支付费用,只用了不到一秒的时间。页面上购买。 钟先生,付款显示已进入之前设立的网络游戏网站的账户。 整个过程只需十分钟左右,但通过该程序也可以捕获付款人的账户和密码以及所选的建行财付通信息。
禁止“钓鱼网站”

在“药发”网站上,记者发现该网站还提供了针对钓鱼网站的在线测试,但发现该网页点击后很难打开。 对此,该网站客服也坦言“所有测试人员已被关闭,现在我们正在打击这项业务”,但在向记者出售钓鱼程序的过程中,客服并没有隐瞒。根本不。 从记者的采访过程来看,所有“钓鱼程序”的卖家都是在线联系卖家,确认订单后直接通过财付通付款,这也是让买家放心的关键。
据悉,记者在不少网上帖子中还发现,不仅直接订购“钓鱼节目”亲自操作,还有不少线上“钓鱼”正在招募线下“订购者”。 据知情人士透露,所谓“拉单者”就是为网购者提供“鱼”,将“网购”提供的各种“钓鱼链接”和“钓鱼木马”发送给网购者。 输入“在线”账户,然后将“在线”按照一定比例分成“订购者”。 “一般‘线上’是30%,‘下单者’是70%,比如订单被拉了,然后‘线上’消失的情况。”
据上述知情人介绍,做“上网”的人通常会提供一个背景,这比订购“钓鱼链接”更专业。 目前,网上也有大量模仿天猫、模仿中国票务网的网站源代码转让,每套价格从一两千元到三四千元不等。 记者咨询专业网络工程师了解到,通过该源代码程序可以制作类似天猫等网站的网站,而此类网站往往成为“钓鱼网站”的矩阵。 “只要有网络管理员、网络编辑等有能力的人都可以操作,一周之内就可以完成。” 记者还联系了一家转让仿天猫网站源代码的网站,该网站的客服给记者发来了一个自己制作的演示网站(),除了域名中有淘宝字样外,整个网站与正品天猫网站几乎一模一样,具有极大的欺骗性。
钓鱼网站的仿冒目标
据中国反钓鱼网站联盟公布的最新数据,2011年4月,联盟共查处“钓鱼网站”2635个。 去年处理过的。 4月份查处的2635个“钓鱼网站”中,涉及天猫、工商银行、腾讯、央视等的“钓鱼网站”总数占全部举报的93.89%。